Data Processing Pipeline
AWS Glue Data Processing
The Weather Platform uses AWS Glue to transform raw IoT messages into structured datasets.
Processing Flow
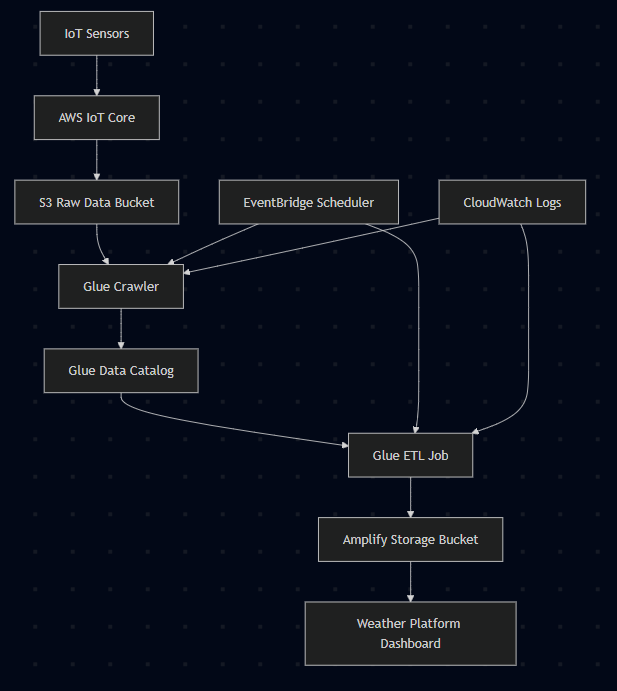
Orchestration Flow:
- EventBridge triggers weekly at midnight UTC+7 (every Sunday)
- Step Functions orchestrates the workflow:
- Starts Glue Crawler to update schema
- Waits for crawler completion
- Starts Glue ETL Job for data transformation
- Export error states (If any)
Glue Components
Database: weather_data_catalog_{unique-suffix}
- Catalogs all weather data schemas
- Automatically discovers table structures
Crawler: WeatherPlatformCrawler-{unique-suffix}
- Scans data lake for new data
- Updates table schemas automatically
ETL Job: WeatherDataTransformJob-{unique-suffix}
- Transforms JSON to CSV format
- Aggregates data by time periods
- Optimizes for analytical queries
ETL Script
The Glue job uses a Python script (weather-transform.py) that:
- Reads raw JSON from data lake
- Normalizes data structure across different devices
- Aggregates data by time windows
- Writes CSV files to processed datasets bucket
Step Functions Orchestration
The data processing workflow uses AWS Step Functions for reliable orchestration:
State Machine Workflow:
// 1. Start Crawler
startCrawler
.next(waitForCrawler) // 2. Wait 2 minutes
.next(checkCrawlerStatus) // 3. Check crawler state
.next(
new stepfunctions.Choice(this, "IsCrawlerComplete")
.when(crawlerComplete, startGlueJob) // 4a. Start ETL job
.when(crawlerRunning, waitForCrawler) // 4b. Continue waiting
.otherwise(crawlerFailed) // 4c. Handle failure
);
Scheduling
Data processing is triggered via EventBridge:
- Frequency: Weekly at midnight UTC+7 (Sundays)
- Trigger: EventBridge cron rule
- Target: Step Functions state machine
- Orchestration: Automated Crawler → ETL Job sequence
Monitoring
Glue jobs provide:
- Execution logs in CloudWatch
- Job success/failure notifications
- Data quality metrics
- Cost tracking
Glue provides serverless data processing - you only pay for processing time used.